
Chair of applied mathematics OQUAIDO
Optimization and uncertainty quantification for expensive data
The research program is at the intersection between the operational goals and scientific limitations described below:
Operational goals
Practical issues arising with expensive-to-evaluate numerical simulators can be gathered in 4 categories:
- Optimization: Finding a point in the input space that minimizes the output value, or that is a good trade-off between various outputs or criteria.
- Inversion: Identifying the set of inputs such that the output is below (or equal to) a given threshold. This problem typically arises when studying probabilities of failure.
- Calibration / validation: Identifying internal parameters of the numerical simulator such that its output matches physical experiments on the real system.
- Uncertainty quantification: Analysing and prioritizing the influence of the inputs (and their interactions) onto the outputs. Computing the probabilities of some events or quantiles.
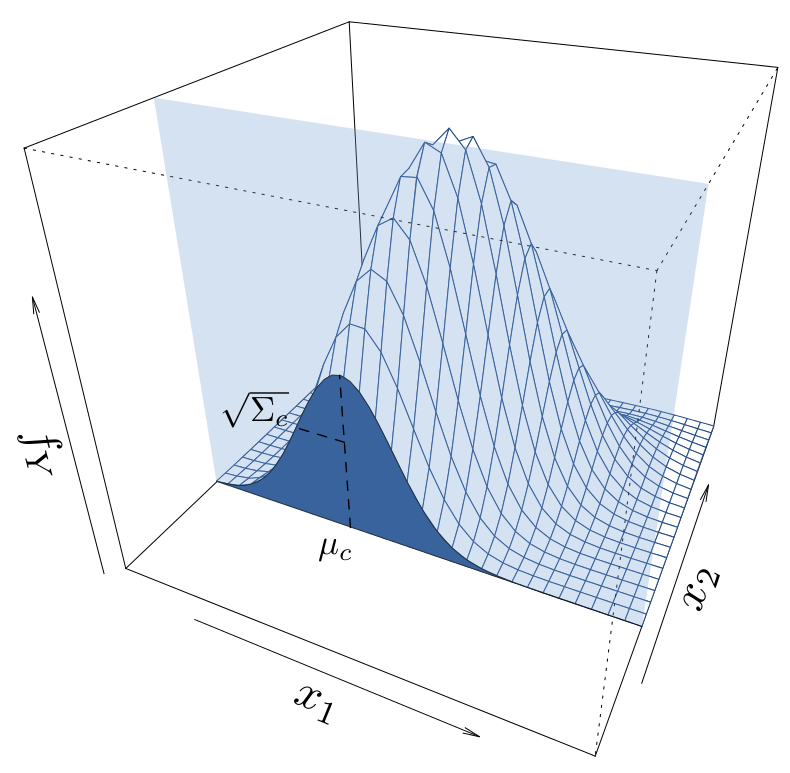
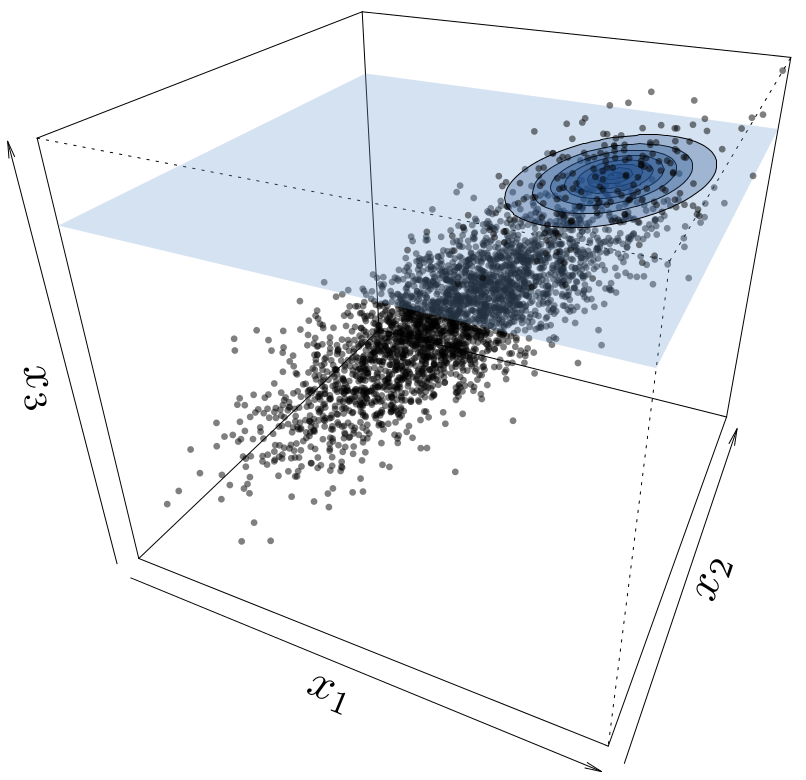
Scientific limitations
The above operational goals are nowadays successfully handled when there is a few (an order of 10) continuous variables. The objective of the Chair is to widen the field of possibilities with a special focus on:
- Categorical inputs. Metamodelling tools are often dedicated to continuous variables and they mostly rely on the distance between training and prediction points. The existence of categorical variables changes the nature of the input space since it contains a discrete set that can be ordered or not. This requires to redefine appropriate distances and but also to use new methods from discrete mathematics.
- Stochastic simulators. This is when the output is random. It thus requires to account for its distribution or some statistics of interest.
- Functional inputs/outputs. The problem is often reduced to finite dimension by using specific functional basis (splines, Fourier, wavelets).
- Large number of inputs. In practice, datasets often consist of tens or hundreds of variables. However, it is quite common that only a few subset of variables has an influence on the output. It is thus important to develop dedicated methods such as functional ANOVA representation or sensitivity analysis.
- Specific constraints. We are currently in the early stage of including constraints (positivity, monotonicity, non-stationarity, ...) into models. This calls for more theoretical work with high potential in applications.
- Large data-sets. Most statistical modelling software have not been conceived to handle large datasets (> 1000 observation points). However, large number of observations is quite common when the simulator is fast enough to be called on extensive designs of experiments.