
Chaire en mathématiques appliquées OQUAIDO
Optimisation et QUAntification d'Incertitude pour les Données Onéreuses
Différentes industries se sont dotées, dans les dernières décennies, de codes de simulation numérique sophistiquées comme outils de prévision, d'optimisation et de décision (simulateurs de fonctionnement de moteurs thermiques, de composants de centrales nucléaires, de production pétrolière, etc.). Ces codes simulant des phénomènes complexes sont de plus en plus réalistes mais ils sont aussi de plus en plus lourds en temps de calcul (parfois plusieurs jours).
L'exploitation de ces codes devient une problématique propre, en particulier lorsque l'objectif poursuivi nécessite un nombre important d'évaluations du code. Ceci est le cas dans les études de propagation d'incertitudes (estimation de l'incertitude des sorties du modèle) et les analyses de sensibilité (connaissance des entrées du modèle les plus influentes sur la variabilité des sorties) mais également dans les études d'optimisation, d'inversion ou de calibration.
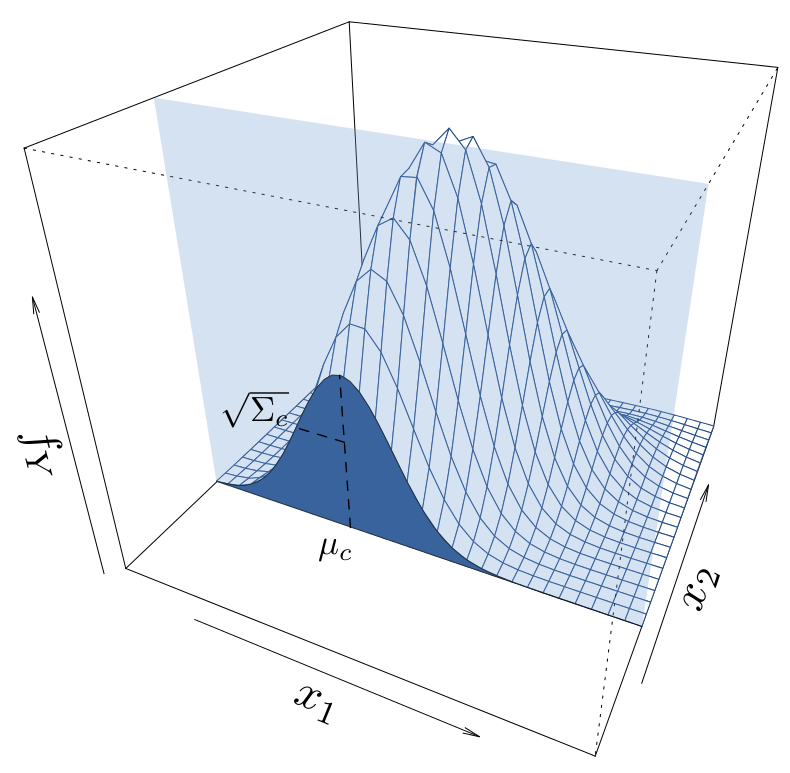
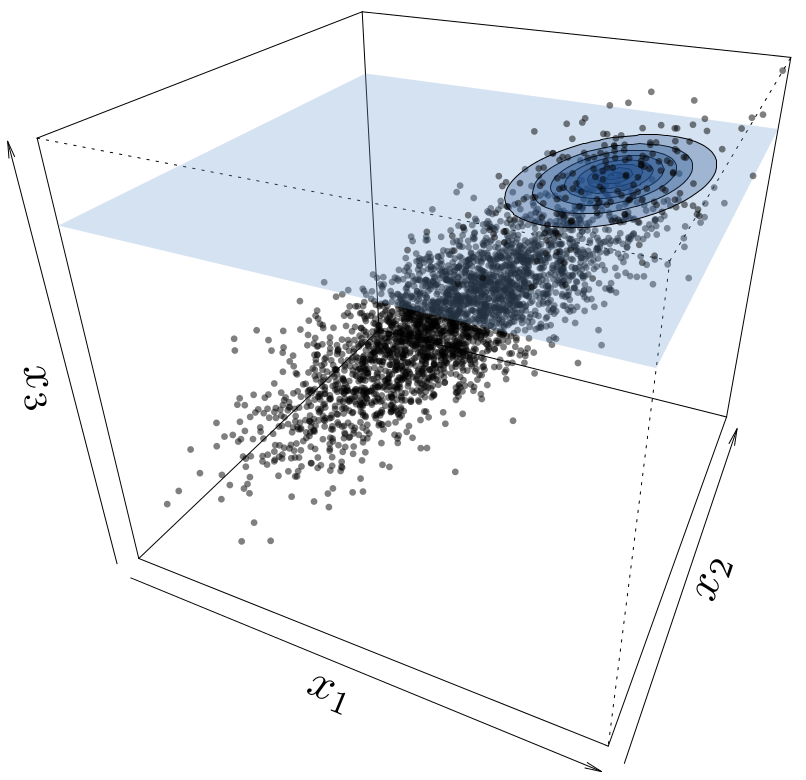
Objectifs opérationnels
Les problématiques pratiques d'exploitation des codes se répartissent en 4 grands axes :
- L’optimisation : trouver un jeu d'entrées optimisant la réponse considérée, ou réalisant le meilleur compromis entre différents critères.
- L’inversion : identifier l'ensemble d'entrées tel que la réponse soit en dessous d'un seuil fixé. Ce problème apparaît typiquement lorsque l'on s'intéresse à des domaines de défaillance.
- La calibration / validation : identifier les paramètres internes du simulateur tels que la réponse simulée s'approche au mieux d'expériences réelles en prenant en compte leurs incertitudes.
- La quantification d'incertitudes : analyser, hiérarchiser la sensibilité des entrées (et de leurs interactions) sur la (les) réponse(s), calculer des risques (probabilité, quantile).
Verrous scientifiques
Aujourd'hui les objectifs opérationnels sont traités avec succès dans le cas d'un petit nombre d'entrées (de l'ordre de la dizaine) de nature continues. La chaire se donne pour objectif d'élargir le champ des possibles en se concentrant notamment sur :
- Les entrées catégorielles. Les outils de méta-modélisation sont surtout développés pour les variables continues, et font souvent intervenir la distance aux points d'apprentissage pour prédire dans des zones inexplorées. La présence de variables catégorielles change la nature de l'espace des entrées, qui contient alors un ensemble discret, ordonné ou non. Cela amène à redéfinir des distances appropriées mais aussi à utiliser de nouvelles techniques issues des mathématiques discrètes.
- les codes stochastiques. C'est le cas où la sortie est de nature aléatoire. Il faut alors considérer sa loi de probabilité, caractérisée par une fonction aux propriétés particulières.
- les entrées/sorties fonctionnelles. Les entrées et/ou de sorties fonctionnelles sont le plus souvent traitées en se ramenant au cas de la dimension finie par projection ou décomposition dans des bases de fonctions appropriées (splines ou ondelettes par exemple).
- Le grand nombre d'entrées. Les problèmes réels font parfois intervenir plusieurs dizaines ou centaines d'entrées. Lorsque seulement quelques entrées (ou interactions) sont réellement influentes, l'exploitation d'un petit nombre de données est envisageable. Au plan théorique, cela amène à développer des techniques particulières basées sur des décompositions fonctionnelles de type ANOVA, l'analyse de sensibilité ou la pénalisation.
- Les contraintes spécifiques. La prise en compte de contraintes (positivité, monotonie, non-stationnarités, ...) en est à ses débuts, et mérite un développement sur le plan théorique mais aussi au regard des objectifs opérationnels.
- Les gros volumes de données. La plupart des logiciels actuels de métamodélisation n'ont pas été conçus pour supporter un grand nombre de données (> 1000), cas encore peu étudié dans la communauté des computer experiments. Une telle adaptation est pourtant utile lorsque le simulateur est suffisamment léger pour permettre la réalisation d'un plan d'expériences très riche.